Machine Learning
Datasets
นำมาจากkaggle geometric shapes mathematicsเป็น dataset เกี่ยวกับรูปทรงเรขาคณิตจำนวน 8 ชุด ได้แก่ "Circle", "Kite", "Parallelogram", "Square", "Rectangle", "Rhombus", "Trapezoid", "Triangle" แบ่งเป็น 1,500 training samples, 500 validation samples 500 test samples จุดประสงค์คือ ต้องการให้ผู้ใช้สามารถวาดภาพและให้โมเดลทายว่ามันคือรูปทรงอะไร
การเตรียมข้อมูล
ทำการเตรียมข้อมูลโดยการปรับภาพให้เป็น สีขาวกับดำ เพื่อให้ง่ายต่อการแยก ทำทั้งชุดสำหรับเทรนและทดสอบ
การเตรียมข้อมูล.py
1import os
2import cv2
3import numpy as np
4import matplotlib.pyplot as plt
5
6train_directory = path+'/dataset/train'
7plt.figure(figsize=(15, 15))
8
9for subfolder in os.listdir(train_directory):
10 shapes_directory = os.path.join(train_directory, subfolder)
11
12 for image_name in os.listdir(shapes_directory):
13 image_path = os.path.join(shapes_directory, image_name)
14 img = cv2.imread(image_path)
15 gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
16 _, binary_img = cv2.threshold(gray_img, 200, 255, cv2.THRESH_BINARY)
17 cv2.imwrite(image_path, binary_img)
18

Encode and Split Data for Training and Testing
encode ชุดข้อมูลให้เป็น 0 กับ 1 และปรับเป็น array 1 มิติ และทำการ encode label ทำทั้งชุดสำหรับเทรนและทดสอบ
Encoder_TrainData.py
1train_directory = path+'/dataset/train'
2X=[]
3Y=[]
4
5for subfolder in os.listdir(train_directory):
6 shapes_directory = os.path.join(train_directory, subfolder)
7 for image_name in os.listdir(shapes_directory):
8 image_path = os.path.join(shapes_directory, image_name)
9 img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
10 pixel_values = img.flatten()
11 X.append(pixel_values)
12 Y.append(subfolder)
13
14X=np.array(X)
15X[X == 0] = 1
16X[X > 200] = 0
17X[X != 0] = 1
18
encodeLabel.py
1mapping = {'rectangle': 0, 'parallelogram': 1, 'trapezoid': 2, 'square': 3,'circle': 4, 'kite': 5, 'triangle': 6, 'rhombus': 7}
2Y = [mapping.get(x, -1) for x in Y]
3Y_test = [mapping.get(x, -1) for x in Y_test]
4
Encoder_TestData.py
1test_directory = path+'/dataset/test'
2X_test=[]
3Y_test=[]
4
5for subfolder in os.listdir(test_directory):
6 shapes_directory = os.path.join(test_directory, subfolder)
7
8 for image_name in os.listdir(shapes_directory):
9 image_path = os.path.join(shapes_directory, image_name)
10 img = cv2.imread(image_path)
11
12 gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
13 _, binary_img = cv2.threshold(gray_img, 200, 255, cv2.THRESH_BINARY)
14 pixel_values = binary_img.flatten()
15 X_test.append(pixel_values)
16 Y_test.append(subfolder)
17
18X_test=np.array(X_test)
19X_test[X_test == 0] = 1
20X_test[X_test > 200] = 0
21X_test[X_test != 0] = 1
22
KNN (K Nearest Neighbors)
โมเดลแรกที่เลือกใช้คือ KNN n_neighbors = 5 การทำงาน โมเดลจะทำการเลือกจุดที่อยู่ใกล้ที่สุดจำนวน 5 จุด และเลือกผลลัพธ์ที่เหมือนกันมากที่สุดมาสรุปผล

KNN_MODEL.py
1from sklearn.neighbors import KNeighborsClassifier
2knn_model = KNeighborsClassifier(n_neighbors=5);
3knn_model.fit(X,Y)
4y_pred_knn = knn_model.predict(X_test)
5conf_matrix_knn = confusion_matrix(Y_test, y_pred_knn)
6accuracy_knn = accuracy_score(Y_test, y_pred_knn)
7precision_knn = precision_score(Y_test, y_pred_knn, average="macro")
8recall_knn = recall_score(Y_test, y_pred_knn, average="macro")
9f1_knn = f1_score(Y_test, y_pred_knn, average="macro")LR (LogisticRegression)
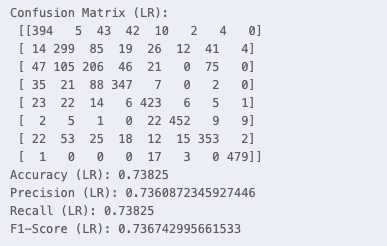
โมเดลที่สอง คือ LogisticRegression max_iter = 10000 เลือกใช้โมเดลนี้เพราะมีขนาดเล็กและทำงานได้ไวมีผลลัพธืที่ค่อนข้างสูง การทำงานจำแนกประเภท (Classification) โดยใช้ฟังก์ชัน Sigmoid ในการแปลงค่าของข้อมูลอินพุตให้เป็นค่าความน่าจะเป็น และตัดสินใจผลลัพธ์
LR_MODEL.py
1from sklearn.linear_model import LogisticRegression
2model = LogisticRegression(max_iter=10000)
3model.fit(X, Y)
4y_pred_LR = model.predict(X_test)
5conf_matrix_LR = confusion_matrix(Y_test, y_pred_LR)
6accuracy_LR = accuracy_score(Y_test, y_pred_LR)
7precision_LR = precision_score(Y_test, y_pred_LR, average="macro")
8recall_LR = recall_score(Y_test, y_pred_LR, average="macro")
9f1_LR = f1_score(Y_test, y_pred_LR, average="macro")